Everything you need to know about federated learning: Why and how to get started?
Posted 2 Dec 2020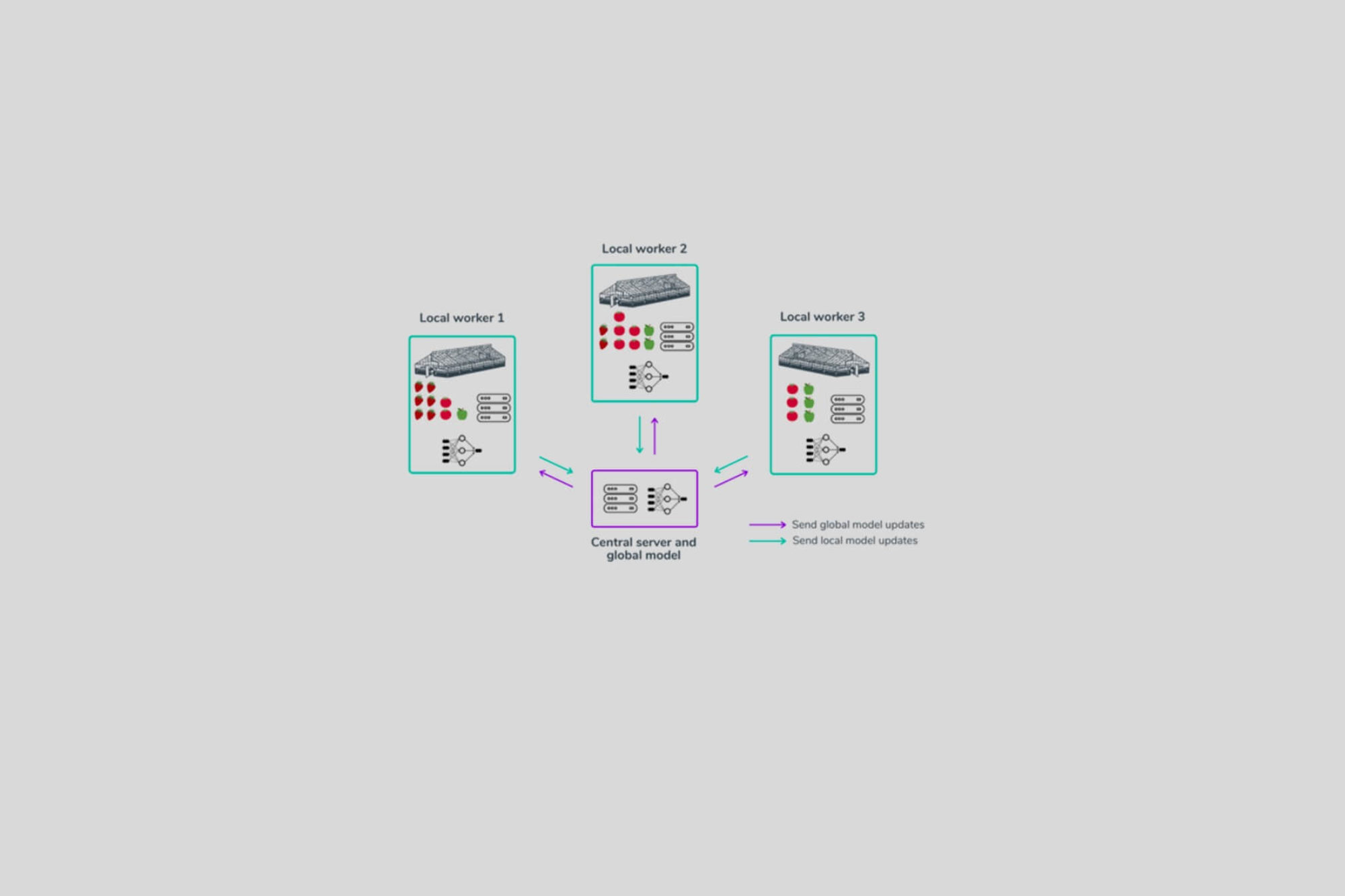
Federated learning (FL) is a technique that aims to train machine learning (ML) algorithms across multiple devices, each of them holding their own private data locally.
Federated learning offers a broader design for implementing machine learning solutions which will essentially provide a more flexible way for data to be managed. The technique can be used in a variety of contexts and works by adapting the way the training procedures for those algorithms are implemented and can be used for both online and offline learning. Federated learning works with lots of different techniques, depending on the type of data and operational context.
An example of a simple federated learning method is federated averaging algorithm consisting of averaging at regular intervals the weight of neural networks trained by different federated learning participants from their local data subsets to update their global model. Using this technique to train machine learning algorithms enables the collaborative development of more robust and better performing ML models while addressing critical issues and challenges around data transfer and sharing, data privacy and security.
Machine learning requires the collection of large amounts of data to solve specific problems but can be costly, challenging and time consuming. Adopting FL techniques within businesses and teams can be useful to overcoming these barriers. FL is a flexible paradigm for implementing machine learning in a distributed and private-preserving setting, which makes FL a great solution to the current challenges and limitations artificial intelligence and data science teams are facing. FL tries to solve the problem of building a machine learning model that is trained on data distributed across many different workers without collecting or moving the data from the central location. The model is located at a central server and that server is in charge of guiding the federated learning process. The workers are usually located at different locations, which could be different networks or even different physical locations. Whilst training the model located at the central server, the data never leaves the worker at which it originates.
It is important to understand the typical steps the central server in FL goes through, in order to understand the full picture. The central server processes data from different sets of workers. The data each worker contains can be very different for each one. That is why the central server is responsible for creating the global machine learning model that uses the data from the workers without ever seeing or transferring data to the central location.
The detailed way this is achieved depends on the fundamental algorithm, but typically the general process consists of the steps below.
- Step 1: The local models at the workers are updated by using the private local data.
- Step 2: The workers send the local updates to the central server.
- Step 3: The server gathers the local updates and adds it to the global model.
- Step 4: The server sends the global model to all the workers.
- Step 5: The workers integrate the global model into their local model.
Finally, in step 5 each worker incorporates the update received from the server into its own local model. This step depends on the federated learning algorithm and the platform chosen to implement the local model.
From the above steps we can identify the following dependencies on the components of the federated learning system identified.
- 1: Application + Implementation platform
- 2: Federated learning algorithm + implementation platform
- 3: Independent of both the federated learning algorithm and the platform
To find out how to build a healthy ecosystem for federated learning within industry, starting from an open and platform independent library, click here.